Roberto PelleritoHi, I'm Roberto, I’m PhD student in Computer Science at the Robotics and Perception Group, University of Zurich and ETH Zürich supervised by Professor Davide Scaramuzza. I’m also co-founder of Ememe where I work on generative animations. My primary interests are in efficient and robust neural network architecture and representation learning. Broadly, I applied these concepts on Visual Odometry, Object Detection and Tracking and Human Pose Estimation. In 2021, I graduated cum laude from a B.Sc in Control Engineering at Politecnico di Milano in Italy. During my bachelor I co-founded Automation Engineering Association @ PoliMi In 2023 I earned a M.Sc. in Robotics, Systems and Control from ETH Zurich in Switzerland. During my master I researched at the Robotics Systems Lab under Prof. Marco Hutter and at Robotics and Perception group under Professor Davide Scaramuzza. I worked for Disney Research in Zurich in 2022 developing algorithms for human pose estimation and animations. I have been teaching assistant at IDSC for the Duckietown course from 2023 to 2024. |

|
Workshop Organization |
Workshop on Neuromorphic Robotic Systems (NeuRoSys)In conjunction with RSS 2026 / Monday, July 13, 2026 / Sydney, Australia I am co-organizing NeuRoSys 2026, a workshop focused on neuromorphic sensing, perception, navigation, planning, and control for real-world robotic systems. The workshop brings together researchers working on event-driven and biologically inspired robotic pipelines, with an emphasis on efficient autonomy, low-latency perception, and integrated hardware-software demonstrations. website / organizers / contributions / announcement / |
PublicationsA series of published work from my research |
Motion-aware Event Suppression for Event CamerasRoberto Pellerito, Nico Messikommer, Giovanni Cioffi, Marco Cannici, Davide Scaramuzza RSS 2026, 2026 arxiv / paper / video / code / website / We introduce the first framework for Motion-aware Event Suppression, which learns to filter events triggered by independently moving objects and ego-motion in real time. The model jointly segments independently moving objects in the current event stream while predicting their future motion, enabling anticipatory suppression of dynamic events before they occur. The lightweight architecture achieves 173 Hz inference on consumer-grade GPUs with less than 1 GB of memory usage, outperforming previous state-of-the-art methods on the challenging EVIMO benchmark by 67% in segmentation accuracy while operating at a 53% higher inference rate. The method also accelerates Vision Transformer inference by 83% via token pruning and improves event-based visual odometry accuracy, reducing Absolute Trajectory Error by 13%. |
|
|
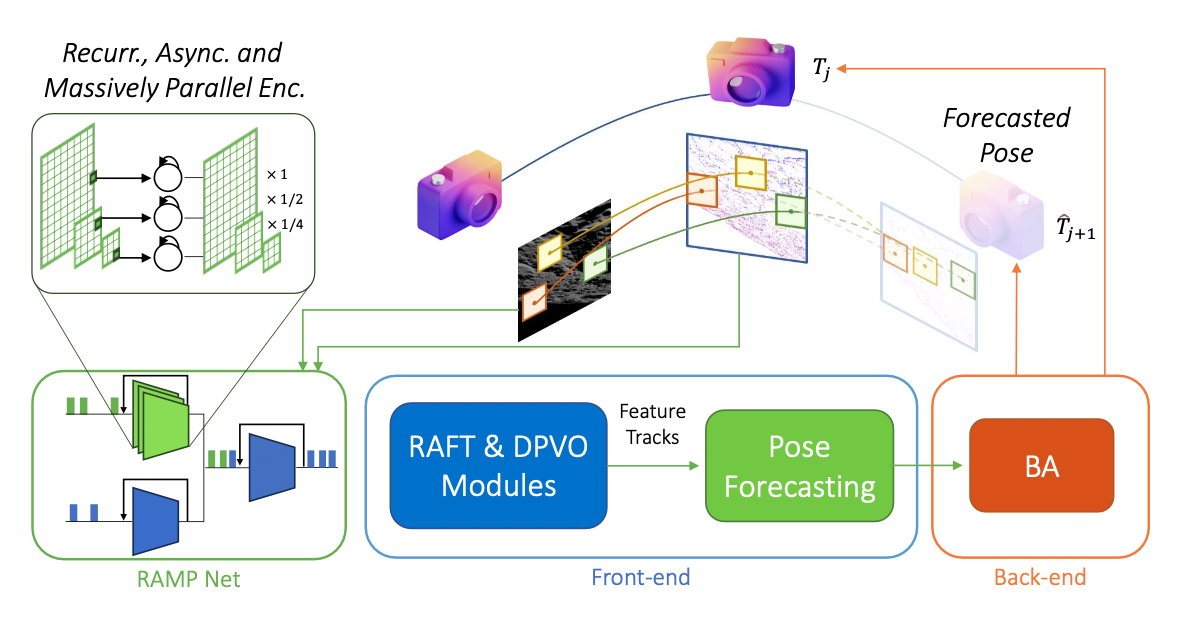
End-to-End Learned Event- and Image-based Visual OdometryRoberto Pellerito, Marco Cannici, Daniel Gehrig, Joris Belhadj, Olivier Dubois-Matra, Massimo Casasco, Davide Scaramuzza IROS 2024 (Oral Presentation), 2024 arxiv / paper / video / code / We introduce RAMP-VO, the first end-to-end learned image- and event-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders capable of fusing asynchronous events with image data, providing 8× faster inference and 33% more accurate predictions than existing solutions, paving the way for robust and asynchronous VO in space. Despite being trained only in simulation, RAMP-VO outperforms previous methods on the newly introduced Apollo and Malapert datasets, and on existing benchmarks, where it improves image- and event-based methods by 58.8% and 30.6%, paving the way for robust and asynchronous VO in space. |
Company projectsA series of projects that I developed in collaboration with companies. |

|
Generative AI Society Simulation with automatic stories creationSociety simulation with mind intervention 2023-10-01 website / video / video #2 / I created together with my team at Ememe a: Learning Based RPG Life Simulation with generative NPCs behavior and Automated story creation. All the characters are commanded by LLMs, they have thoughts, they can reason and have a will. They also share memories and can act with the world the same way the main character does. Users can interact with NPCs by injecting natural language thoughts inside them. Each new character living in this town can be created ground-up: by setting their personalities, their aspirations, their daily schedules and their looks and animations. |

|
Multi-human motion predictionHuman pose estimation 2022-06-01 website / I worked on enhancing multi-human pose estimation and motion prediction. The objective was to use a system of cameras, to accurately reconstruct and predict poses for different humans in the scene. |
Unpublished projectsA series of projects that for time constraints or other reasons have not been published. |

|
Quadruped robot with a compliant fore-leg for enhanced mobilitySecond version of the tendon-driven quadruped robot for testing leg compliance and distributed control Roberto Pellerito 2024-09-06 website / video / code / The aim of this project is mainly do design my first working (and walking) robot, soon I will publish a youtube video explaining my journey. I started by design using Shapr3D the leg of the robot. My objective was to put all servos higher up to decrease inertia of the leg. Then I designed a part (You can see in the video the low-diameter stick connecting the higher part of the leg with lower part) which should server as shock absorption as it is made of a semi-flexible PLA. Then I tried different configurations and design of the leg, printing them and finally settled for the current. At this point I started to design the body of the robot, which is basically the hull of an extruded ellipse. I designed the body such that can be printed in two parts which then can be assembled together. This to avoid wasting material of my 3d printer. In the current stage I printed the first half of the body, connected the first leg to it and tested the electronics that should control the legs. |

|
Unsupervised Zero-Shot Pose Estimationzero-shot object pose estimation pipeline Roberto Pellerito, Alessandro Burzio, Lorenzo Piglia, Diego Machain 2022-10-01 paper / code / slides / we present a zero-shot object pose estimation pipeline extending the work of OnePose that leverages self- supervised deep learning methods like DINO to produce pose estimates for everyday objects, even those that have not been seen during training. We deploy our full pipeline on the Microsoft HoloLens 2 as an interactive application, enabling real-time pose estimation of objects in the user’s environment. Our approach demonstrates the potential for using self-supervised deep learning methods to enable robust and accurate object pose estimation in a zero-shot setting. |

|
Panoptic video segmentation with vision transformers for mobile robotsSegmentation and Tracking with Video Transformers for Mobile Robots Roberto Pellerito, Marco Hutter 2022-02-01 slides / In this work, we investigate a solution to speed up model inference of novel vision Transformers for segmentation and object tracking. First, we focus on state of the art network used for object detection and image segmentation: DETR. We develop an approach to convert the model from PyTorch to TensorRT that can reduce the computational cost and memory footprint signifi- cantly. Second, we investigate DETR’s potential towards online object instance segmenta- tion by investigating TrackFormer, a model that by itself makes use of DETR. We can show promising results in the video segmentation domain, and train the model using small datasets for tracking a specific objects. |

|
Omnidirectional quadruped robotFirst version of my quadruped robot -> Spider Bot Roberto Pellerito 2021-02-16 code / The aim of this was to put my hands dirty on a real project. So when covid was bursting I ordered my first 3D printer assembled it and printed the parts. I have designed them based on the model of RegisHsu https://www.thingiverse.com/thing:2204279. I used really cheap MG90 actuators which were barely able to sustain battery and electronics. I designed the electronic schematics on my own and soldered the parts in a punched board. Basically one intake was receiving the power from a 12V battery, which was distributed to power the arduino Uno and the servos. Unfortunately the servos required at leash 1A of current and 5V to function correctly, so I also attached a transformer to higher the current provided by thr batteries. After designing the walking gate I have done a small obstacle avoidance algorithm. It was taking the absolute distance from an echo-sensor and as long as the distance was lower than a threshold it was turning the robot to the right or to the left for an amount of time. |